



总结起来基本上就两个原因:
1、数据库的问题,数据量大后,查询检索效率低下。
成都全市人口超过2000万,每天一次核酸,那就是单日新增两千万条记录,最近几天一直在做,数据容量很快就是几亿的规模,如果后端用MySQL还不分表,那确实够呛。
2、高并发的问题,同一时间大量请求,服务器扛不住。
一般情况下,使用nginx负载均衡,单机能做到几万的并发量。但成都2000W+的人口规模,全面做核酸的情况下,几万的并发肯定是不够用的。
倘若这套系统背后真的就是一个nginx+mysql(不分表),那昨晚的情况也就不足为奇了。
好了,吃瓜归吃瓜,我们还是要来点干货,作为一个程序员,要在吃瓜中学会成长。
高并发之路
1、单机时代
一开始的时候,用户量很少,一天就几百上千个请求,一台服务器就完全足够。
我们用Java、Python、PHP或者其他后端语言开发一个Web后端服务,再用一个MySQL来存储业务数据,它俩携手工作,运行在同一台服务器上,对外提供服务。

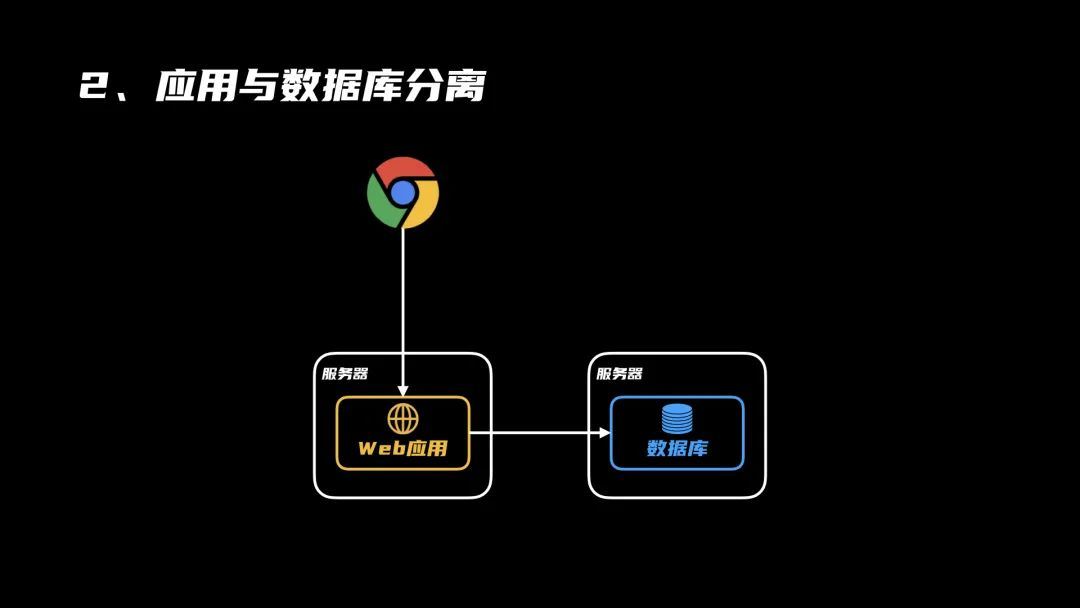
2、应用与数据库分离
慢慢的,用户量开始多了起来,一台服务器有点够呛,把它们拆开成两台服务器,一台专门运行Web服务,一台专门用来运行数据库,这样它们就能独享服务器上的CPU和内存资源,不用互抢了。
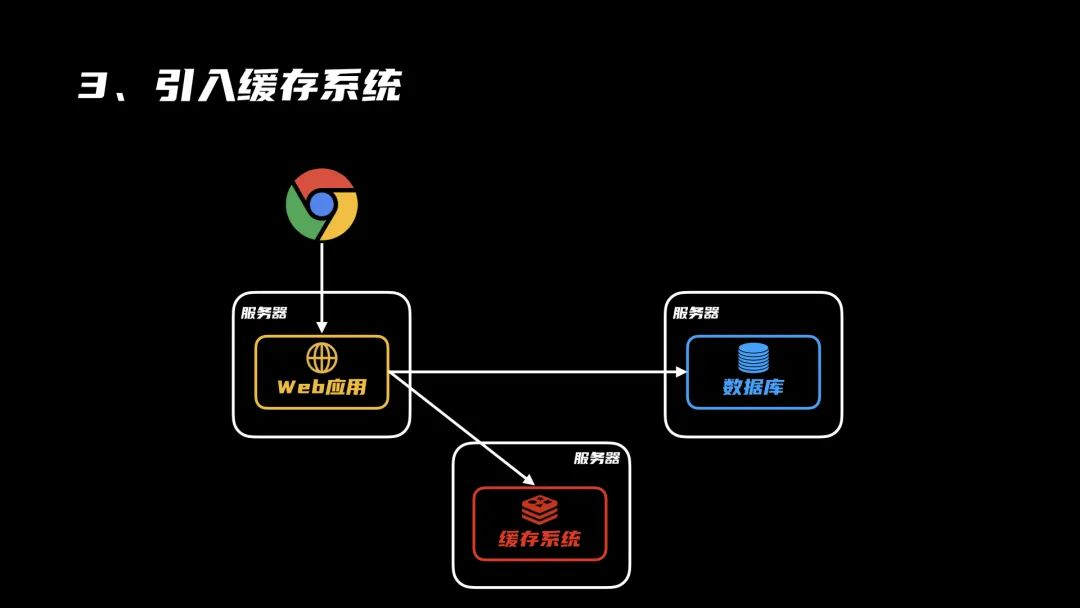
3、缓存系统
后来,用户量进一步增加,每一次都要去数据库里查,有点费时间,引入一个缓存系统,可以有效缩短服务的响应时间。
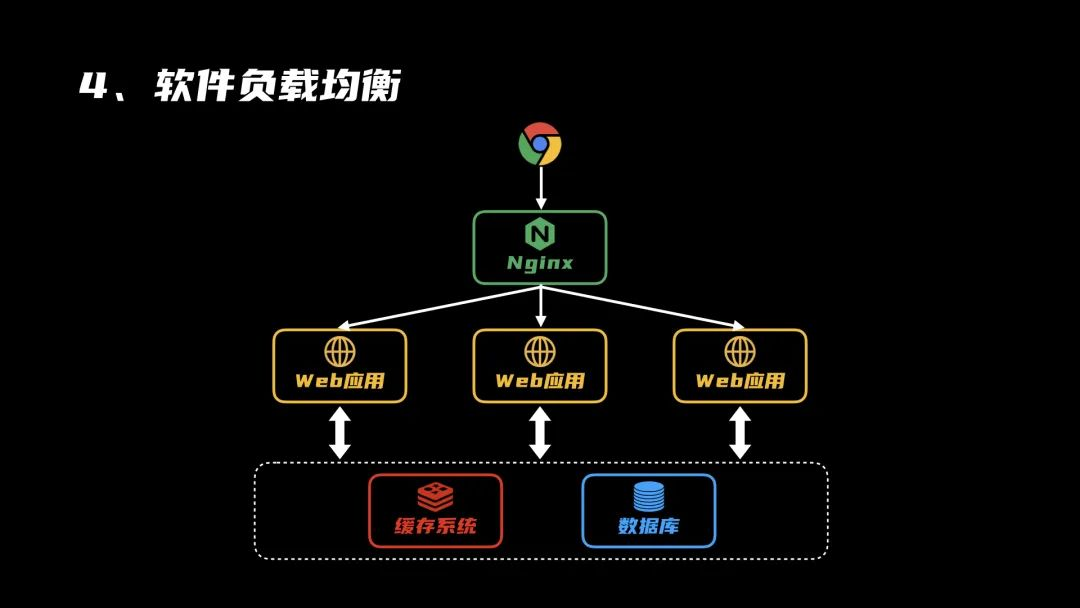
4、软件负载均衡
用户量还在增加,一个Web服务的吞吐量开始达到了上限,系统开始出现卡顿。这时候,可以复制多个Web服务出来,再用一个nginx来进行负载均衡,将请求分摊到所有Web服务器上,提高并发量。
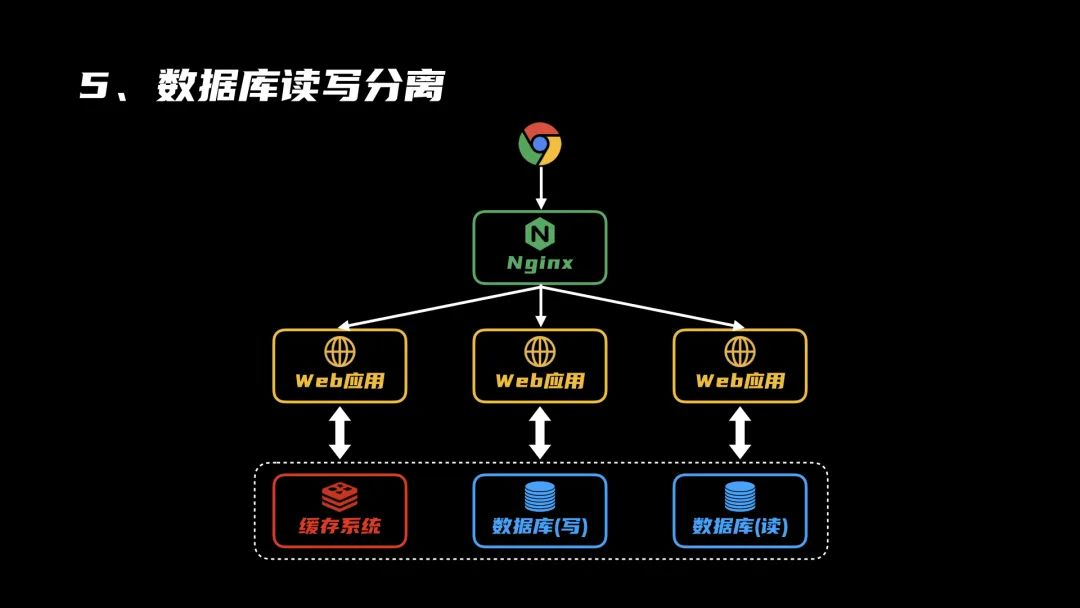
5、数据读写分离
随着系统的运行和用户的增长,数据量越来越多,数据库的瓶颈开始显现,读写明显变慢。这时候,可以增加新的数据库服务器,将读写进行分离,二者做好数据同步,提高数据库服务的整体I/O性能。
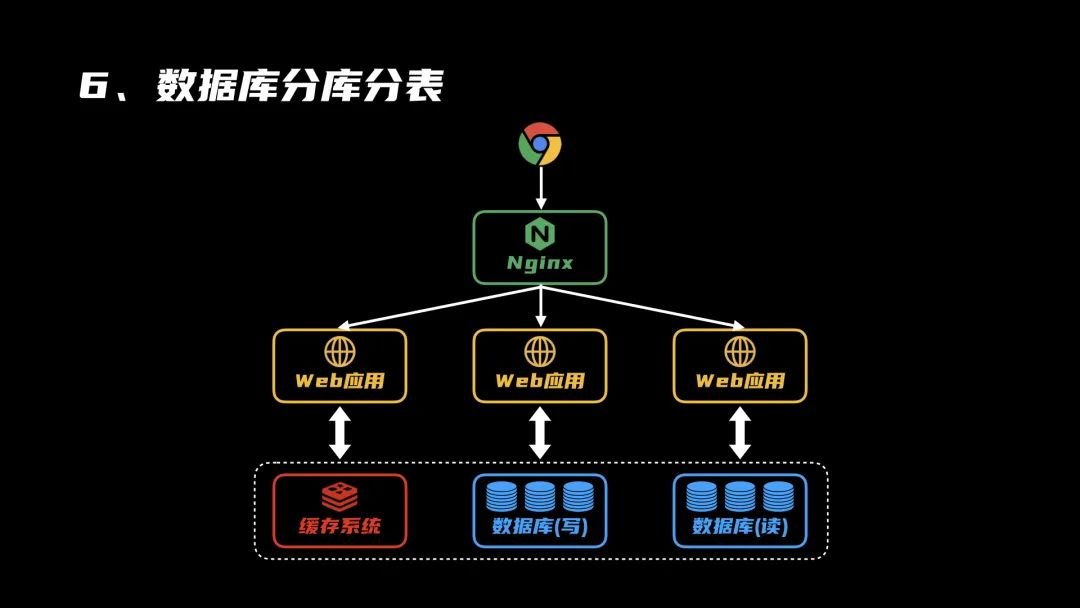
6、数据库分库分表
系统中的数据越来越多,即便是读写分离了,但一张表中的记录越来越多,从几百万到几千万,甚至要过亿了。把它们全部塞在同一张表里,检索查询耗时费力,是时候进行分库分表,把数据拆分一下,提高数据查询效率。
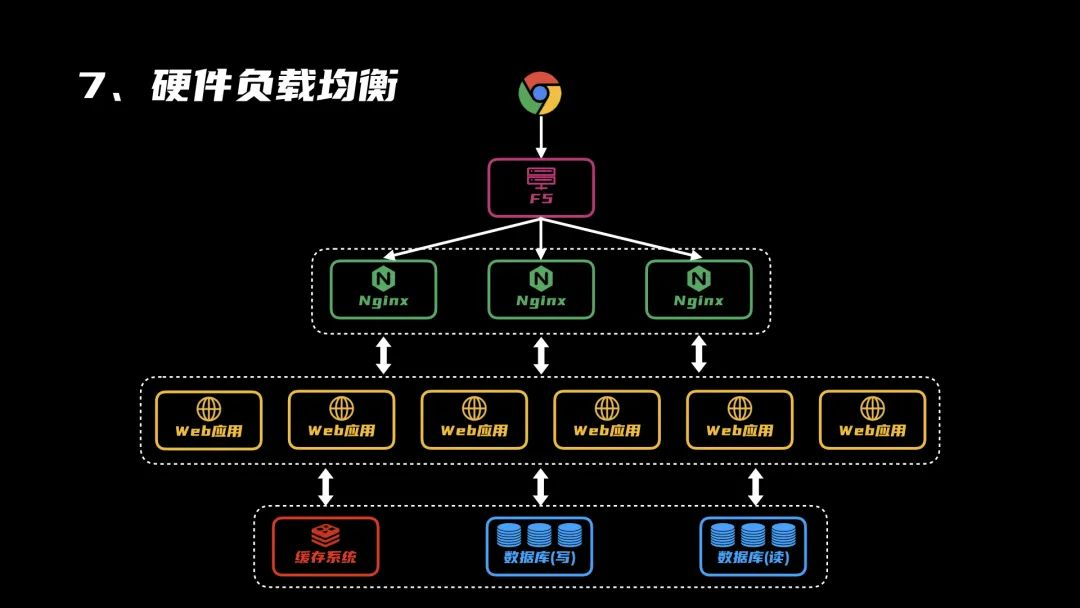
7、硬件负载均衡
再后来,业务发展很不错,用户量激增,以至于强劲的Nginx也扛不住了。
一台不够,那就多整几台,再引入一个硬件负载均衡的服务器,比如F5,将网络流量分发到不同的Nginx服务器上,再一次提高性能。
8、DNS负载均衡
再再后来,用户量还在蹭蹭蹭的增长,强悍如F5这样的硬件负载均衡服务器也扛不住这样的高并发。
老办法,一个不够那就多整几个。这一次,咱们在域名解析上下功夫,不同地区的用户,在访问同一个域名时,解析到不同的IP地址,以此来将流量进一步拆分。

评论区